
蒸馏 - 模型蒸馏
模型蒸馏(Model Distillation)是一种在机器学习和深度学习中使用的模型压缩技术,目的是在保留模型性能的前提下,将复杂的“大”模型简化成更小、更高效的模型。这个过程涉及将一个称为“教师模型(Teacher Model)”的大模型中的知识传递给一个较小的“学生模型(Student Model)”。
知识蒸馏(Knowledge Distillation, KD),将教师网络(teacher network)的知识迁移到学生网络(student network)上,使得学生网络的性能表现如教师网络一般。我们就可以愉快地将学生网络部署到移动手机和其它边缘设备上。通常,我们会进行两种方向的蒸馏,一种是from deep and large to shallow and small network,另一种是from ensembles of classifiers to individual classifier。
参考资料
知识蒸馏算法综述

压缩已训练好的模型:
- 把一个已经训练好的臃肿的网络进行瘦身
- 权值量化:把模型的权重从原来的32个比特数变成用int8,8个比特数来表示,节省内存,加速运算
- 剪枝:去掉多余枝干,保留有用枝干。分为权重剪枝和通道剪枝,也叫结构化剪枝和非结构化剪枝,一根树杈一根树杈的剪叫非结构化剪枝,也可以整层整层的剪叫结构化剪枝。
- 把一个已经训练好的臃肿的网络进行瘦身
直接训练轻量化网络
- 在设计时就考虑哪些算子哪些设计是轻量化的
加速卷积运算
- 在数值运算的角度来加速各种算子的运算
- 比如im2col+GEMM,就是把卷积操作转成矩阵操作,矩阵操作是很多算法库里内置的功能,比如py,tf和matlab都有底层的加速到极致的矩阵运算的算子
- 在数值运算的角度来加速各种算子的运算
硬件部署
- 用英伟达的TensorRT库,把模型压缩成中间格式,部署在Jetson开发板上;Tensorflow-slim和Tensorflow-lite是tensorflow轻量化的生态;因特尔的openvino;FPGA集成电路也可以部署人工智能算法
基础概念
dark knowledge:指那些隐藏在教师模型软输出(soft outputs)中的细微模式和关系,它为提高学生模型的表现提供了额外的信息来源。
logits: 在分类问题中,神经网络的输出通常被称为logits。Logits是指神经网络最后一层(通常是全连接层)应用激活函数之前的原始输出值。
损失函数(Loss Function) 是机器学习和深度学习中的核心概念,用于量化模型预测结果与真实值之间的差异。通过最小化损失函数,模型可以逐步调整参数以提升预测的准确性。
Softmax:一种激活函数,通常用于多分类问题的神经网络输出层。它将模型的输出转化为概率分布,使得所有输出的概率值之和为 1。对于给定的输入向量 𝑧 , Softmax 函数的公式
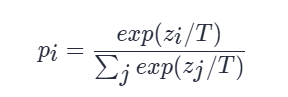
其中,T 控制输出分布的平滑度,当T变大时,类别之间的差距变小;当T变小时,类别间的差距变大。zi代表分类i的模型分数。在训练时对学生网络和教师网络使用同样temperature T,在推理时,设置T=1,恢复为标准的softmax。
当 temperature 为 1 时,为 hard targets,即未进行软化。
知识的表示与迁移

把左边的马图像喂给分类模型,会有很多类别,每个类别识别出一个概率,训练网络时,我们只会告诉网络,这张图片是马,其余是驴,是汽车的概率都是0,这个就是hard targets。
用hard targets训练网络,但这就相当于告诉网络,这就是一匹马,不是驴不是车,而且不是驴不是车的概率是相等的,这是不科学的。若是把马的图片喂给已经训练好的网络里面,网络给出soft targets这个结果,是马的概率为0.7,为驴的概率为0.25,为车的概率是0.05,所以soft targets就传递了更多的信息。
hard targets | soft targets(涵盖信息更多)
马 1 0.7
驴 0 0.25
汽车 0 0.05
tips:
- Hard Targets:提供的是确定性的信息,即每个样本严格属于某一类别。
- Soft Targets:有时也称为“概率性标签”,它们提供了关于样本可能属于各个类别的不确定性信息。
- Soft Label包含了更多“知识”和“信息,像谁,不像谁,有多像,有多不像,特别是非正确类别概率的相对大小
所以训练教师网络的时候就可以用hard targets训练,训练出了教师网络之后,教师网络对这张图片的预测结果soft targets能够传递更多的信息,就可以用soft targets去训练学生网络。
引入蒸馏温度T,把原来比较硬的soft targets变的更软,更软的soft targets去训练学生网络,那些非正确类别概率的信息就暴露的越彻底,相对大小的知识就暴露出来,让学生网络去学习:
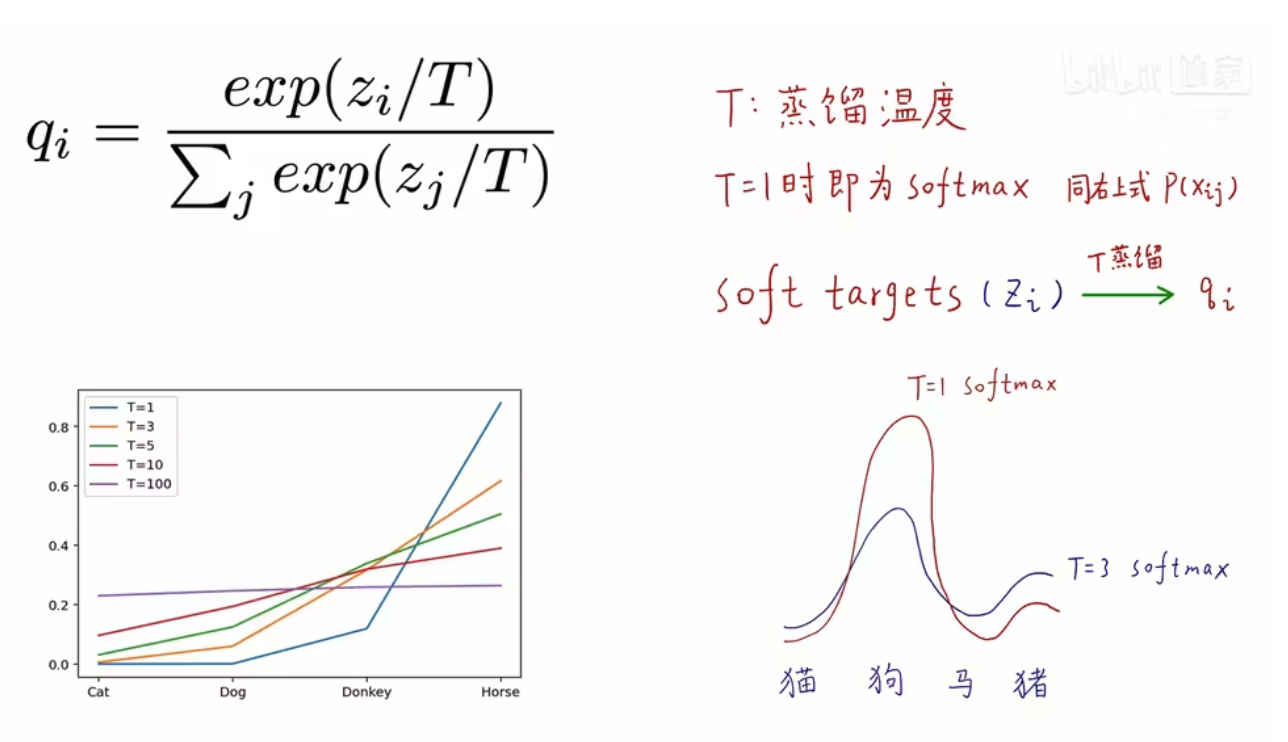
T为1,就是原softmax函数,softmax本来就是把每个类别的logic强行变成0-1之间的概率,并且求和为1,是有放大差异的功能,如果logic高一点点,经过softmax,都会变的很高。
T越小,非正确类别的概率相对大小的信息就会暴露的更明显;T越大,曲线就会变得更soft,高的概率给降低,低的概率会变高,贫富差距就没有了。