
RAG - 基础
参考资料
概念
检索增强生成(Retrieval Augmented Generation,简称 RAG)是一种结合了检索和生成的模型架构,旨在通过检索外部知识库来增强生成模型的能力。 RAG 最初由 Facebook AI 提出,广泛应用于问答、对话生成等任务。
背景
- 训练数据导致的幻觉
- 知识过时 (涵盖的知识止步于大语言模型训练的时间截面)
- 知识边界(无法覆盖垂直领域)
- 知识偏差(数据可能存在不实和偏见)
- 模型自身导致的幻觉
- 知识长尾 (训练数据中部分信息的出现频率较低,导致模型对这些知识的学习程度较差)
- 曝光偏差 (由于模型训练与推理任务存在差异,导致模型在实际推理时存在偏差)
- 对齐不当:在模型与人类偏好对齐阶段中,偏好数据标注不当可能引入了不良偏好
- 对齐:是指让模型的目标、行为和价值观与人类设计者的意图和价值观保持一致。
- 解码偏差:模型解码策略中的随机因素可能影响输出的准确性
上述幻觉问题极大地影响了大语言模型的生成质量。这些问题的成因主要是大语言模型缺乏相应的知识或生成过程出现了偏差,导致其无法正确回答。
基本架构
RAG 通常集成了外部知识库(Corpus)、信息检索器(Retriever)、生成器(Generator,即大语言模型)等多个功能模块。
主要模块:
- 检索模块:从外部知识库(如维基百科)中检索与输入相关的文档或段落。
- 生成模块:基于检索到的内容生成最终的输出。
流程:
- 输入一个问题或上下文。
- 检索模块从知识库中检索相关文档。
- 生成模块结合检索到的文档和输入,生成最终答案。
原始 RAG 方法
简而言之,RAG 结合了搜索技术和大语言模型的提示功能,即模型根据搜索算法找到的信息作为上下文来回答查询问题。无论是查询还是检索的上下文,都会被整合到发给大语言模型的提示中。
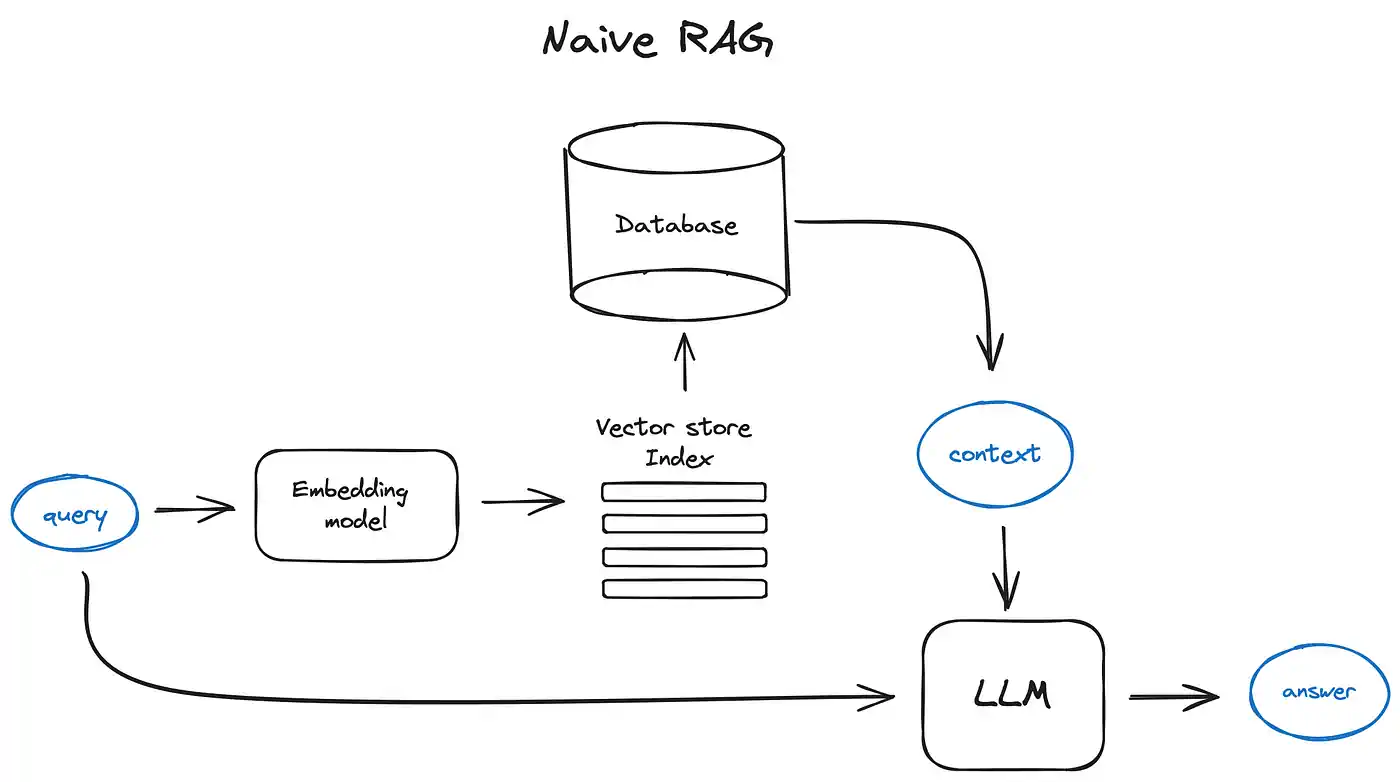
检索: 将文本分割成小块,然后使用某种 Transformer Encoder 模型将这些小块转换为向量,把这些向量汇总到一个索引中,最后创建一个针对大语言模型的提示,指导模型根据我们在搜索步骤中找到的上下文回答用户的查询。
生成:在实际运行中,我们用相同的 Encoder 模型将用户的查询转化为向量,然后对这个查询向量进行搜索,与索引进行匹配,找出最相关的前 k 个结果,从我们的 数据库中提取相应的文本块,并将其作为上下文输入 LLM 进行处理。