
神经网络 - 循环神经网络
参考资料
概念
循环神经网络(Rerrent Neural Network, RNN)是一类具有短期记忆能力的神经网络。在循环神经网络中,神经元不但可以接受其他神经元的信息,也可以接受自身的信息,形成具有环路的网络结构。因此RNN对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,利用了RNN的这种能力,使深度学习模型在解决语音识别、语言模型、机器翻译以及时序分析等NLP领域的问题时有所突破。
核心思想
RNN 的核心在于循环连接(Recurrent Connection),即网络的输出不仅取决于当前输入,还取决于之前所有时间步的输入。这种结构使 RNN 能够处理任意长度的序列数据。
循环网络按照时间线展开:
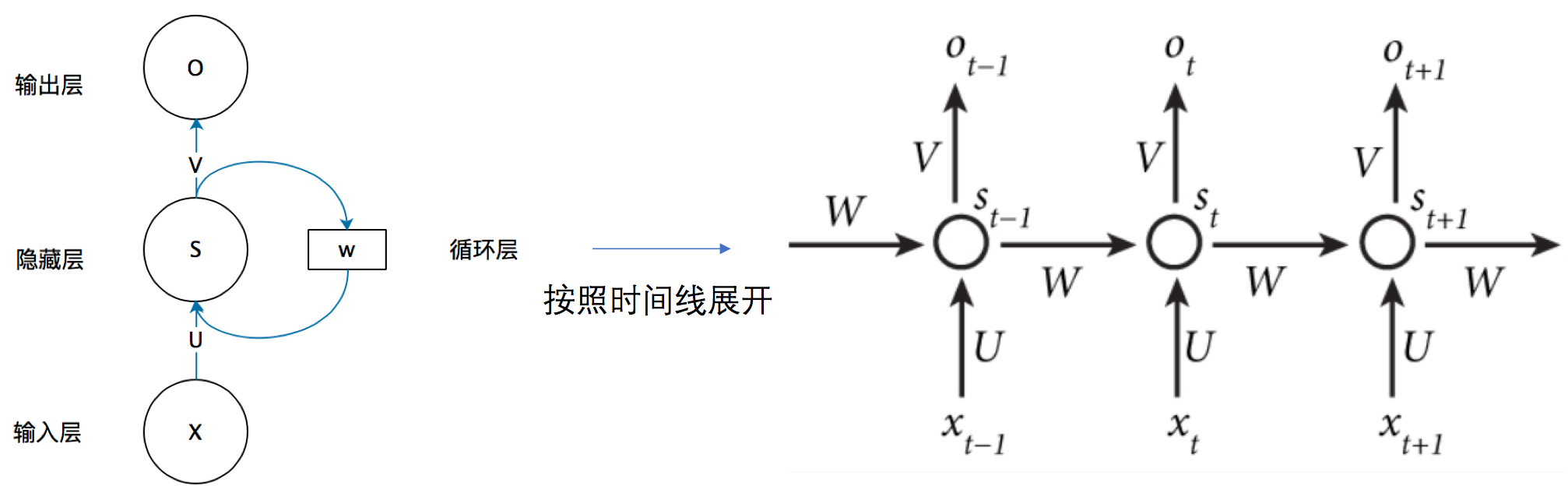
用公式表示:
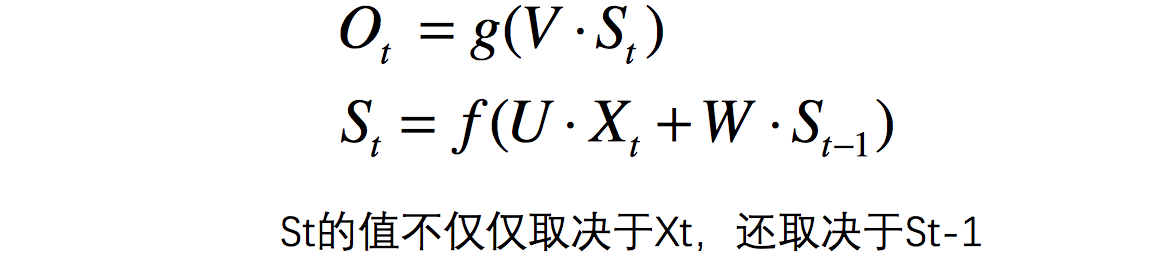
优缺点
优点:
- 能够处理不同长度的序列数据。
- 能够捕捉序列中的时间依赖关系。
缺点:
- 对长序列的记忆能力较弱,可能出现梯度消失或梯度爆炸问题。
- 训练可能相对复杂和时间消耗大。
应用
LSTM 网络
长短期记忆网络(LSTM)是一种特殊的循环神经网络 (RNN),能够学习长期依赖关系。LSTM通过引入一种称为“细胞状态”(Cell State)和三个关键的“门”结构(Gate),有效地控制信息的流动,使得网络可以选择性地记住或忘记信息,从而解决了长期依赖的难题。
所有循环神经网络都由一串重复的神经网络模块组成。在标准循环神经网络 (RNN) 中,这些重复模块的结构非常简单,例如只有一个 tanh 层。
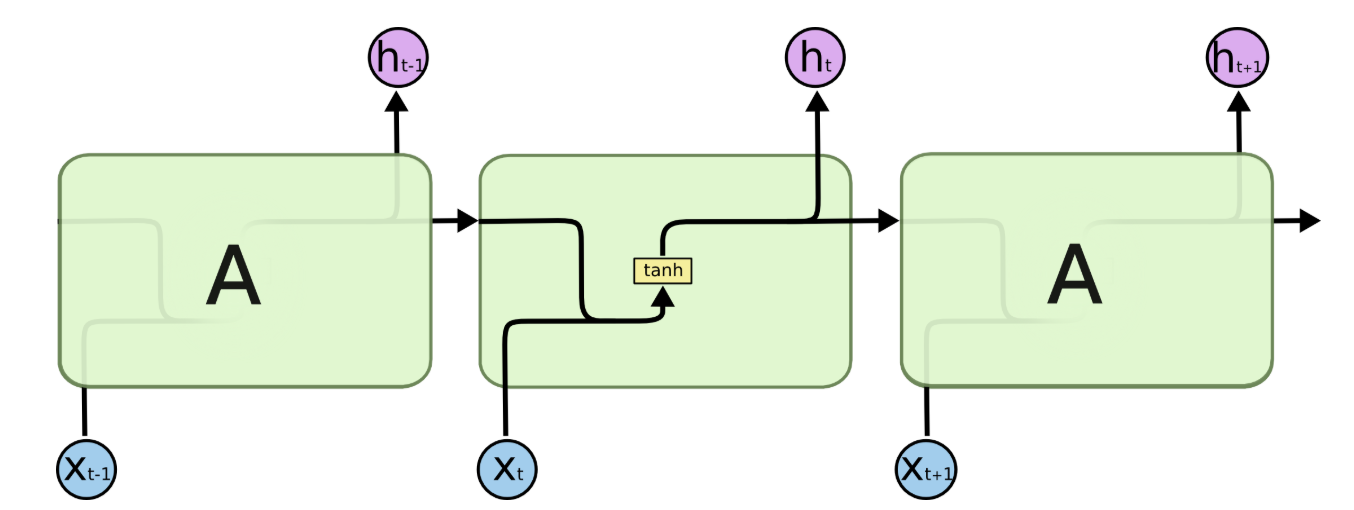
LSTM 也具有这种链式结构,但其重复模块的结构有所不同。它不再只有一层神经网络,而是有四层,并且以一种非常特殊的方式相互作用。
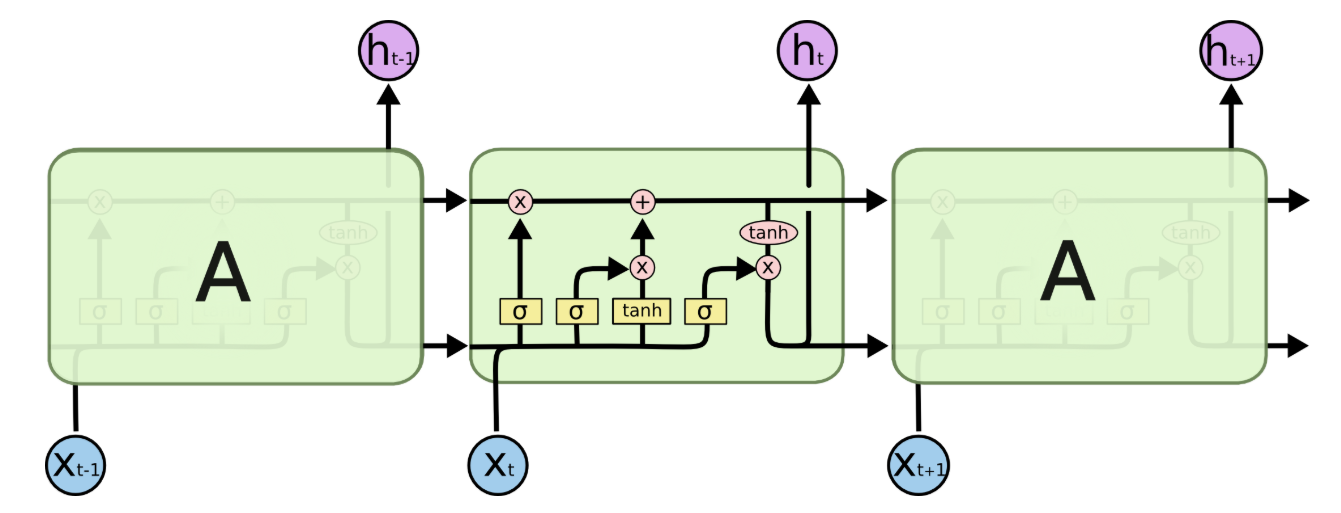
核心思想
LSTM 的关键是细胞状态,即贯穿图表顶部的水平线。
细胞状态有点像传送带。它沿着整个链条直线运行,只有一些微小的线性相互作用。信息很容易不加改变地沿着它流动。
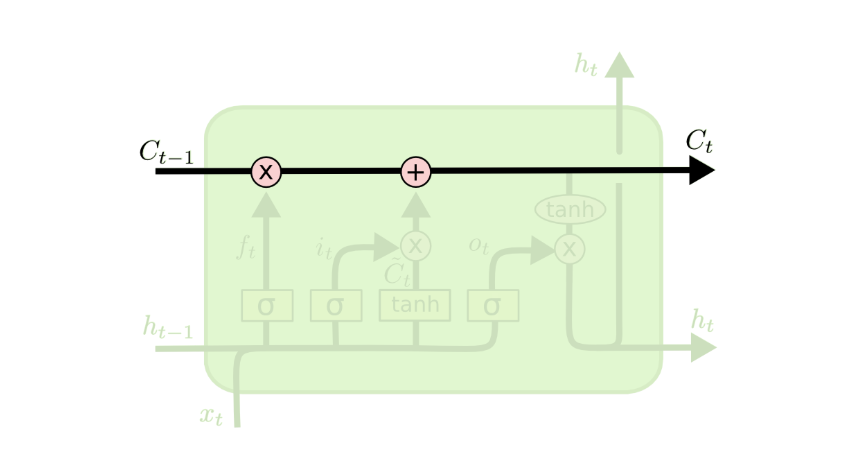
LSTM 确实具有从细胞状态中删除或添加信息的能力,并由称为门的结构精心调节。
门是一种选择性地允许信息通过的方式。它们由一个 S 型神经网络层和一个逐点乘法运算组成:
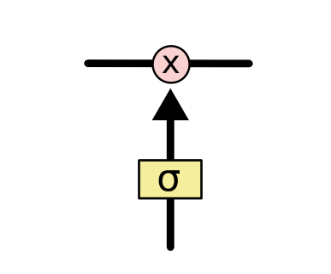
Sigmoid 层输出介于 0 到 1 之间的数字,描述每个组件应该通过的量。0 表示“不让任何组件通过”,而 1 表示“让所有组件通过!”
LSTM 有三个这样的门,用于保护和控制单元状态。
遗忘门(forget gate)
LSTM 的第一步是决定我们需要从 cell 状态中扔掉什么样的信息。这个决策由一个称为“遗忘门(forget gate)”的 sigmoid 层决定。输入 和,输出一个 0 到 1 之间的数。1 代表“完全保留这个值”,而 0代表“完全扔掉这个值”。
比如,对于一个基于上文预测最后一个词的语言模型。cell 的状态可能包含当前主题的信息,来预测下一个准确的词。而当我们得到一个新的语言主题的时候,我们会想要遗忘旧的主题的记忆,应用新的语言主题的信息来预测准确的词。
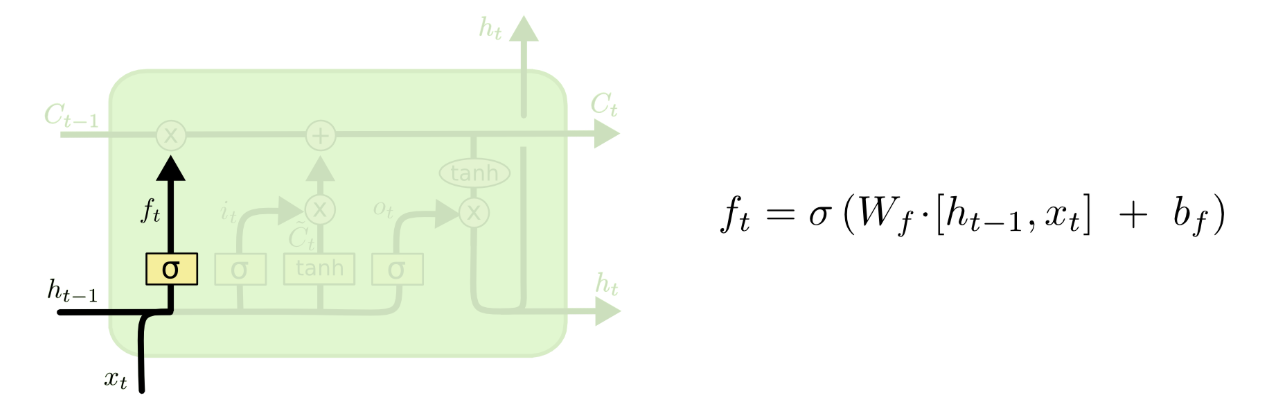
输入门(input gate)
第二步是决定我们需要在 cell state 里存储什么样的信息。这个问题有两个部分。首先 sigmoid 层调用“输入门(input gate)”以决定哪些数据是需要更新的。然后,一个 tanh 层为新的候选值创建一个向量,这些值能够加入 state 中。下一步,我们要将这两个部分合并以创建对 state 的更新。
比如还是语言模型,可以表示为想要把新的语言主题的信息加入到 cell state 中,以替代我们要遗忘的旧的记忆信息。
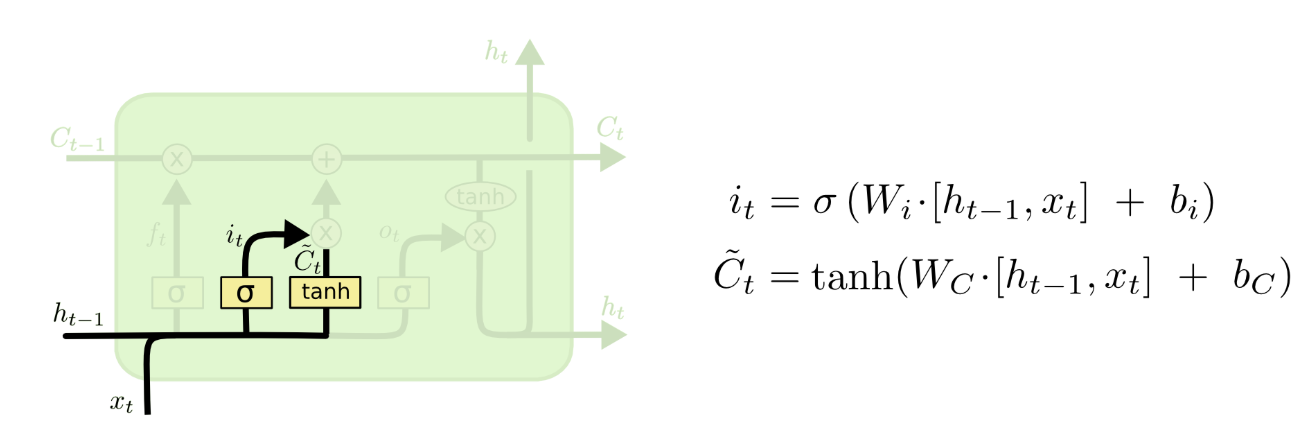
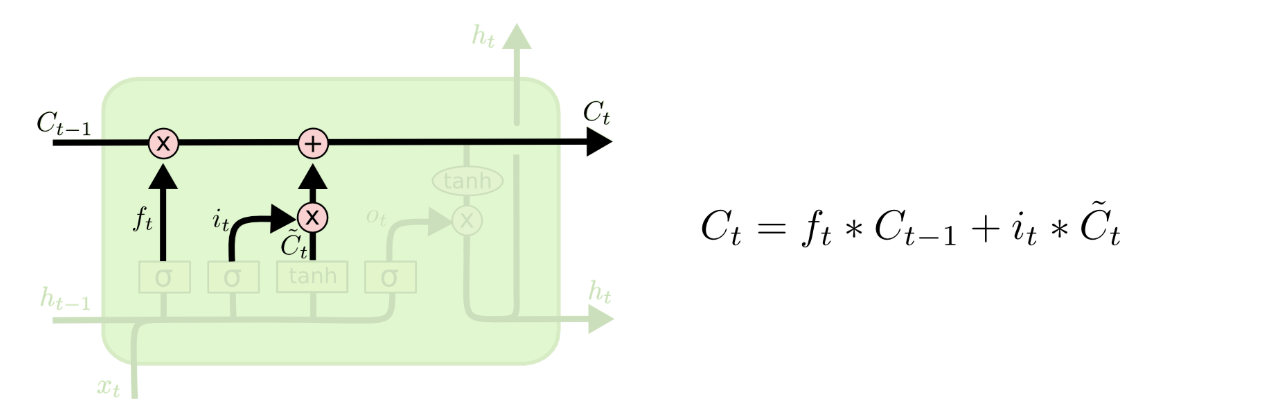
在决定需要遗忘和需要加入的记忆之后,就可以更新旧的 cell state到新的 cell state了。在这一步,我们把旧的 state与相乘,遗忘我们先前决定遗忘的东西,然后我们加上,这可以理解为新的记忆信息,当然,这里体现了对状态值的更新度是有限制的,我们可以把 当成一个权重。
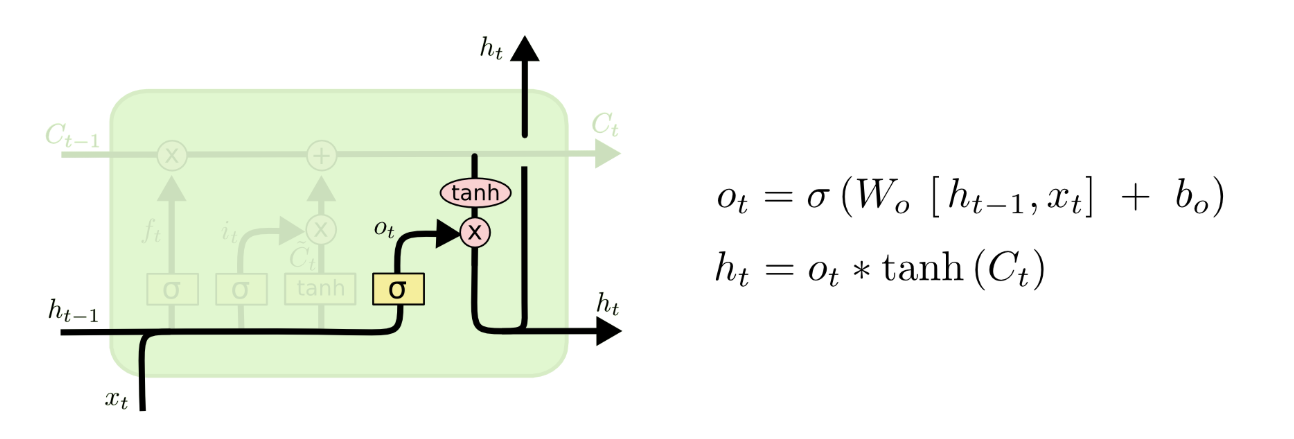
输出门(output gate)
最后,我们需要决定要输出的东西。这个输出基于我们的 cell state,但会是一个过滤后的值。首先,我们运行一个 sigmoid 层,这个也就是输出门(output gate),以决定 cell state 中的哪个部分是我们将要输出的。然后我们把 cell state 放进 tanh(将数值压到-1和1之间),最后将它与 sigmoid 门的输出相乘,这样我们就只输出了我们想要的部分了。
GRU(Gated Recurrent Unit)
GRU(Gated Recurrent Unit)是一种对 LSTM 稍微改进的循环神经网络,由 Cho 等人(2014年)提出。它将遗忘门和输入门合并成一个单一的“更新门”,同时将 cell state 和隐藏状态合并,并进行了其他一些改动。GRU模型相对于标准的 LSTM 模型来说更加简单,并且越来越受到广泛关注和应用。
GRU 与 LSTM 相比,主要的区别在于门控机制的设计。GRU 只使用了一个更新门,通过控制信息的流动和状态的更新,同时减少了参数量和计算量。相比于 LSTM,GRU 模型更加简洁,更容易训练,并且在一些任务上取得了相当好的性能。
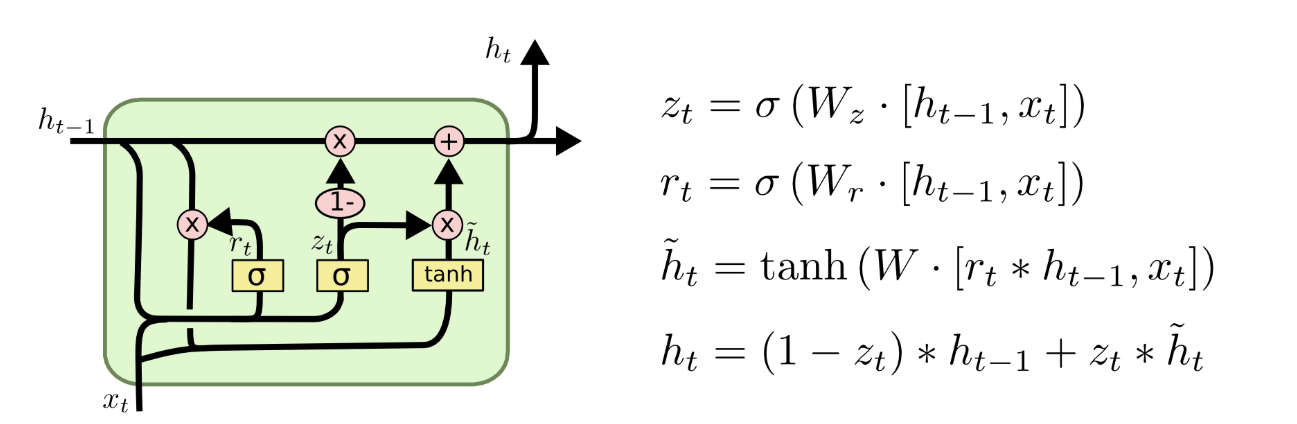
两个门构成,分别是 reset gate和 update gate,需要注意这里与 LSTM 的区别是 GRU 中没有output gate。