
神经网络 - 激活函数
参考资料:
概念
激活函数在神经元中非常重要的。为了增强网络的表示能力和学习能力,激活函数需要具备以下几点性质:
- 连续并可导(允许少数点上不可导)的非线性函数。可导的激活函数可以直接利用数值优化的方法来学习网络参数。
- 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。
- 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
常用的激活函数
下面介绍几种在神经网络中常用的激活函数:
Sigmoid型函数
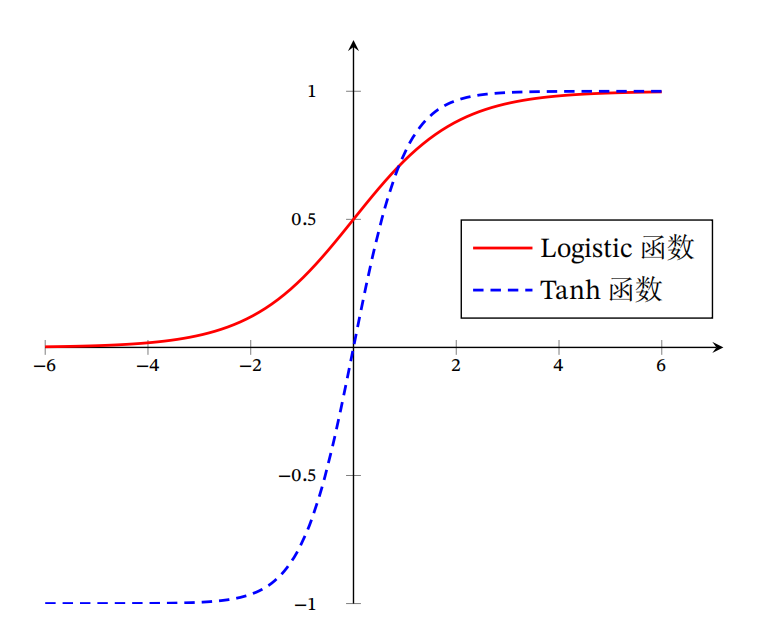
Sigmoid 型函数是指一类 S 型曲线函数,为两端饱和函数。常用的 Sigmoid型函数有Logistic函数和Tanh函数。
备注:对于函数 𝑓(𝑥),若 𝑥 → −∞ 时,其导数 𝑓′(𝑥) → 0,则称其为左饱和.若𝑥 → +∞时,其导数𝑓′(𝑥) → 0,则称其为右饱和.当同时满足左、右饱和时,就称为两端饱和。
Logistic函数定义:
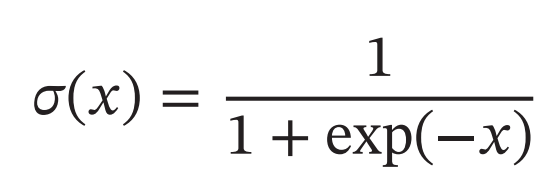
Logistic 函数可以看成是一个“挤压”函数,把一个实数域的输入“挤压”到(0, 1)。当输入值在0附近时,Sigmoid型函数近似为线性函数;当输入值靠近两端时,对输入进行抑制.输入越小,越接近于 0;输入越大,越接近于 1。这样的特点也和生物神经元类似,对一些输入会产生兴奋(输出为1),对另一些输入产生抑制(输出为0)。
Tanh函数也是一种Sigmoid型函数:
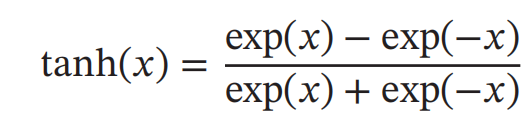
Tanh函数可以看作放大并平移的Logistic函数,其值域是(−1, 1)。
ReLU函数
ReLU(Rectified Linear Unit,修正线性单元),也叫Rectifier函数,是目前深度神经网络中经常使用的激活函数(默认推荐)。
ReLU实际上是一个斜坡(ramp)函数,定义为
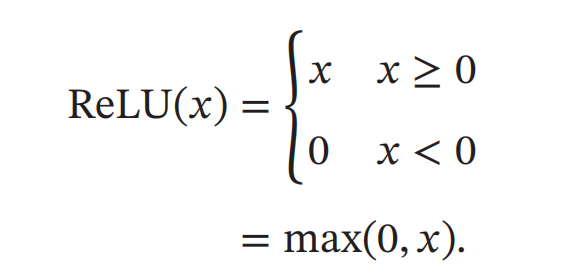
优点:采用 ReLU 的神经元只需要进行加、乘和比较的操作,计算上更加高效。ReLU 函数也被认为具有生物学合理性(Biological Plausibility),比如单侧抑制、宽兴奋边界(即兴奋程度可以非常高)。
缺点 ReLU 函数的输出是非零中心化的,给后一层的神经网络引入偏置偏移,会影响梯度下降的效率。此外,ReLU 神经元在训练时比较容易“死亡”。在训练时,如果参数在一次不恰当的更新后,第一个隐藏层中的某个 ReLU 神经元在所有的训练数据上都不能被激活,那么这个神经元自身参数的梯度永远都会是0。 在以后的训练过程中永远不能被激活.这种现象称为死亡 ReLU 问题(Dying ReLU Problem),并且也有可能会发生在其他隐藏层。
Leaky ReLU
带泄露的ReLU(Leaky ReLU)在输入 𝑥 < 0时,保持一个很小的梯度𝛾。这样当神经元非激活时也能有一个非零的梯度可以更新参数,避免永远不能被激活。带泄露的ReLU的定义如下:
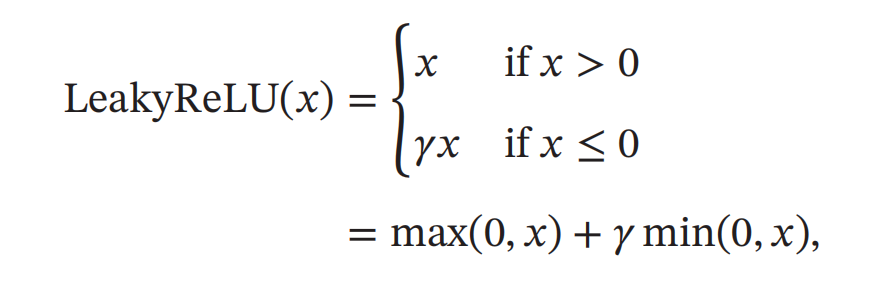
带参数的ReLU
带参数的 ReLU(Parametric ReLU,PReLU)引入一个可学习的参数同神经元可以有不同的参数。对于第 𝑖 个神经元,其 PReLU 的定义为
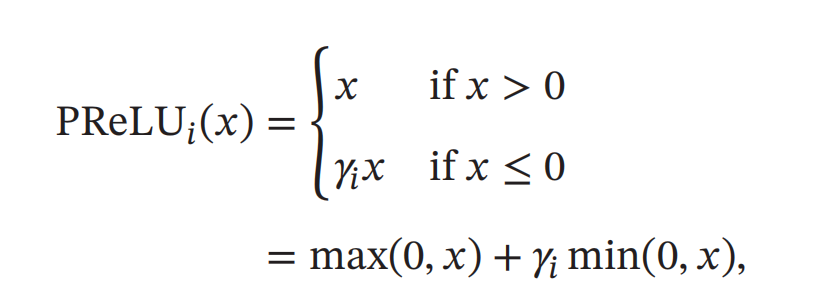
ELU函数
ELU(Exponential Linear Unit,指数线性单元)是一个近似的零中心化的非线性函数,其定义为
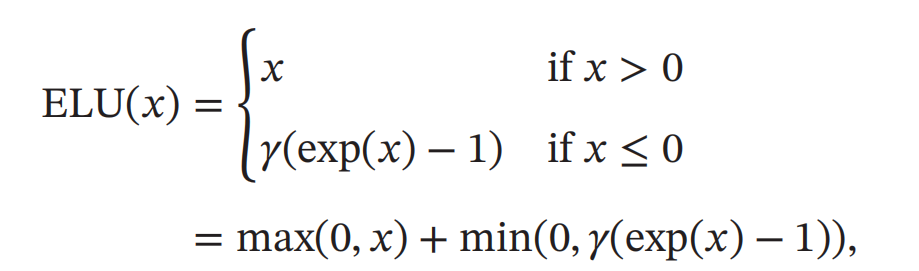
Softplus函数
Softplus 函数可以看作 Rectifier 函数的平滑版本,其定义为
Softplus(𝑥) = log(1 + exp(𝑥))
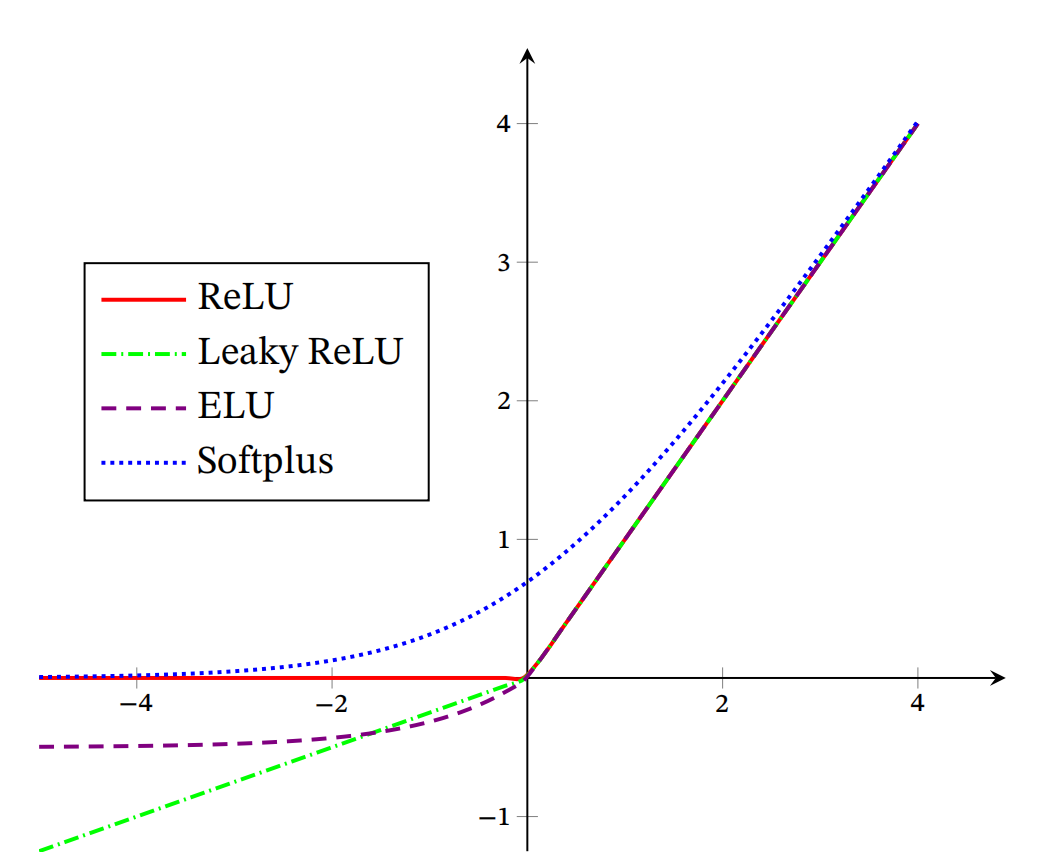
ReLU、Leaky ReLU、ELU以及Softplus函数:
Softmax函数
对于一个给定的实数向量,它首先计算每一个元素的指数(e的幂),然后每个元素的指数与所有元素指数总和的比值,就形成了softmax函数的输出。 这种计算方式不仅使输出值落在0到1之间,还保证了所有输出值的总和为1。
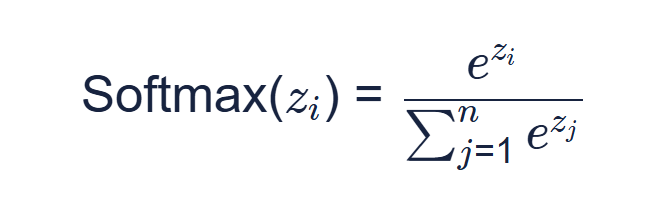
总结
常见的激活函数包括:
- Sigmoid:用于二分类问题,输出值在 0 和 1 之间。
- Tanh:输出值在 -1 和 1 之间,常用于输出层之前。
- ReLU(Rectified Linear Unit):目前最流行的激活函数之一,定义为 f(x) = max(0, x),有助于解决梯度消失问题。
- Softmax:常用于多分类问题的输出层,将输出转换为概率分布。