
基于大模型的代码生成和摘要技术 —— 蔡毅
———— 孙剑 西安交通大学
代码生成
代码生成:将高层级描述、模型或自然语言指令转换为特定语言代码的过程。
传统代码生成流程:人工理解需求、查阅文档手册或在线论坛、编写代码并迭代
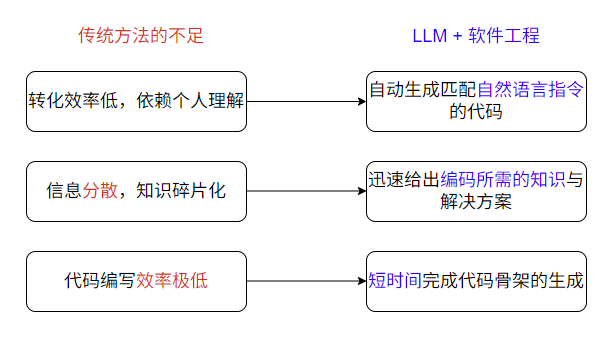
LLM支持很长的上下文窗口,可以理解很多的代码信息。LLM还可以调用工具,以创建新的文件。
LLM可以实现项目级代码补全这样的复杂任务。目前已有一些AIIDE实现了这样的功能,如TRAE、Cursor。
代码摘要
代码摘要即代码的注释,它描述代码的功能。
传统代码摘要流程:人工阅读代码、用自然语言概括代码、维护摘要文档
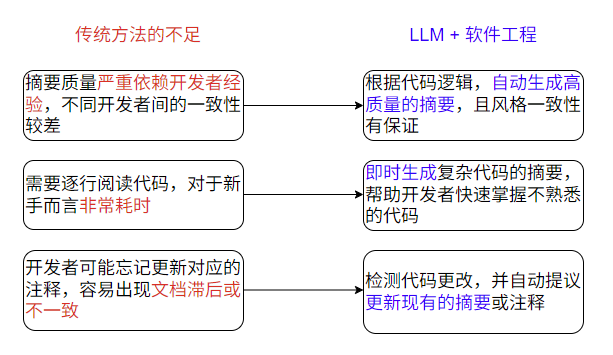
基于注释链与后验证的代码摘要模型
自动代码摘要旨在为源代码生成简洁的自然语言描述(摘要),从而将软件开发人员从繁重的手动注释和软件维护工作中解放出来。
问题:目前的代码摘要方法忽略了代码与文本的异构性
代码片段和摘要是异构的,它们在词汇、或语言结构方面存在很大差异。当尝试直接学习从代码生成摘要的映射时,这种固有的异构性给代码模型带来了巨大的挑战。
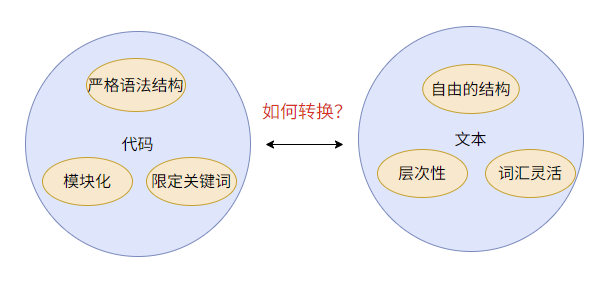
直接从代码转换成摘要面临较大的挑战!
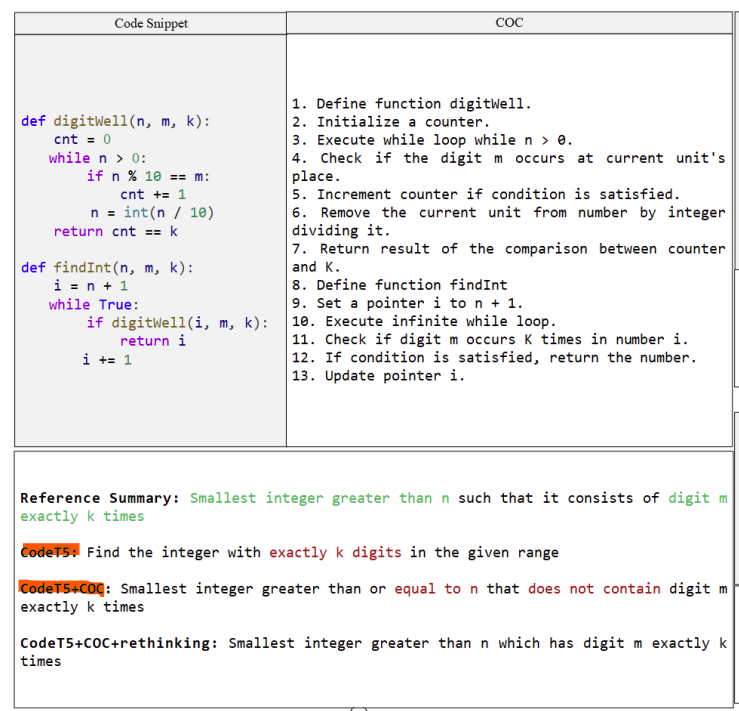
解决思路:引入注释链作为中间表示降低直接从代码转换成摘要的难度
- 不直接生成摘要,而是先生成一系列解释代码逻辑的注释,然后再基于这些注释生成最终摘要
- 引入了“后验证”(Rethinking)机制,对生成的摘要进行重新思考和打分,以选出最佳结果
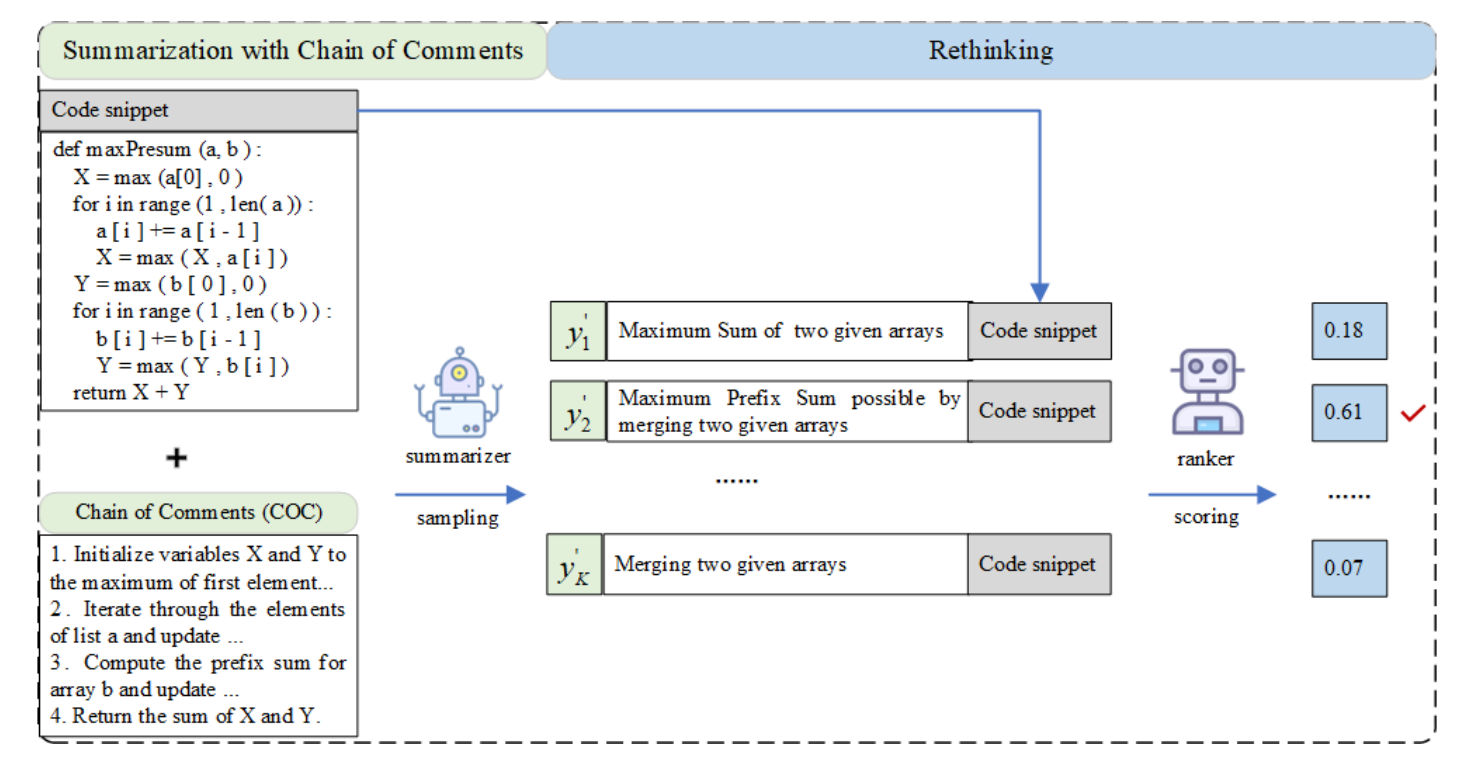
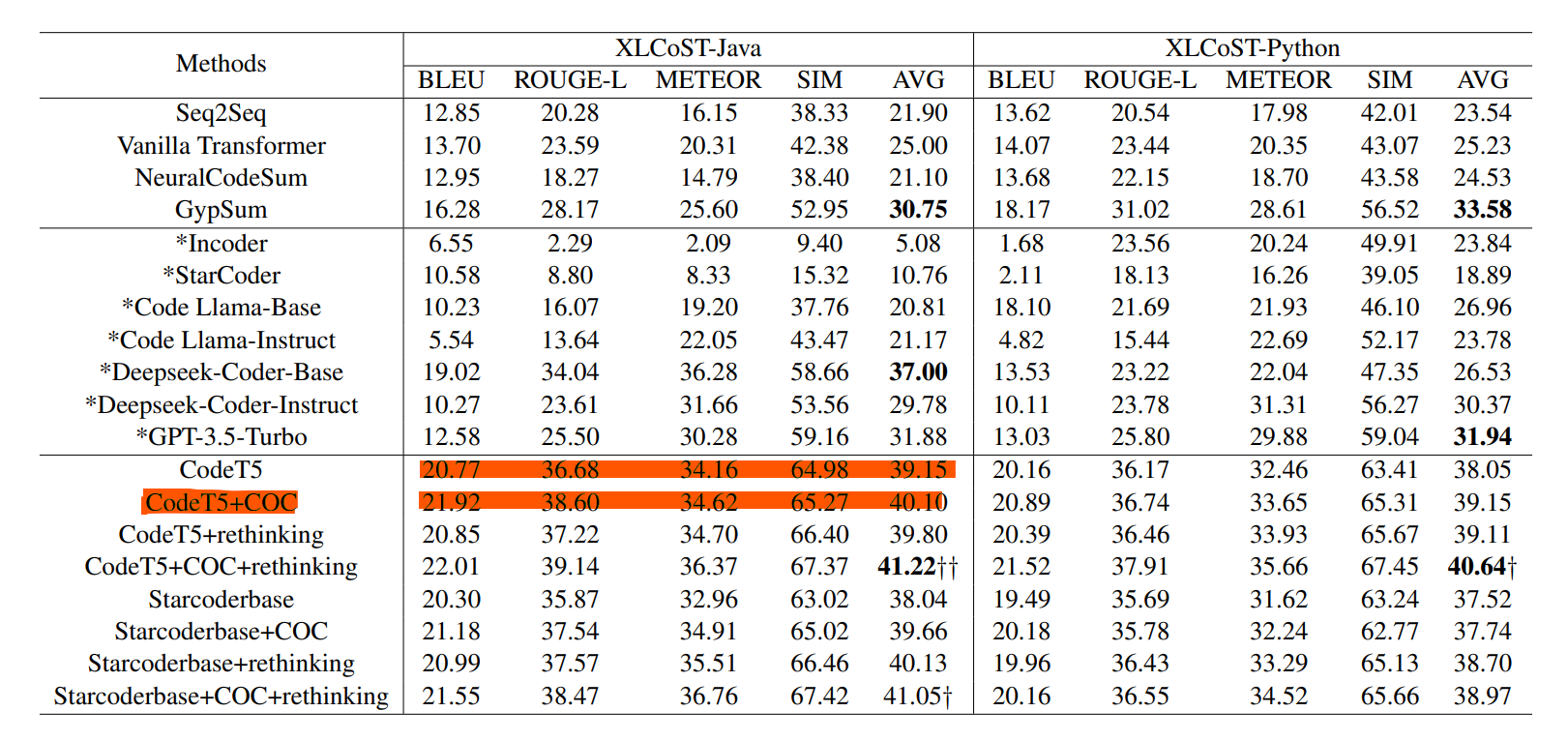
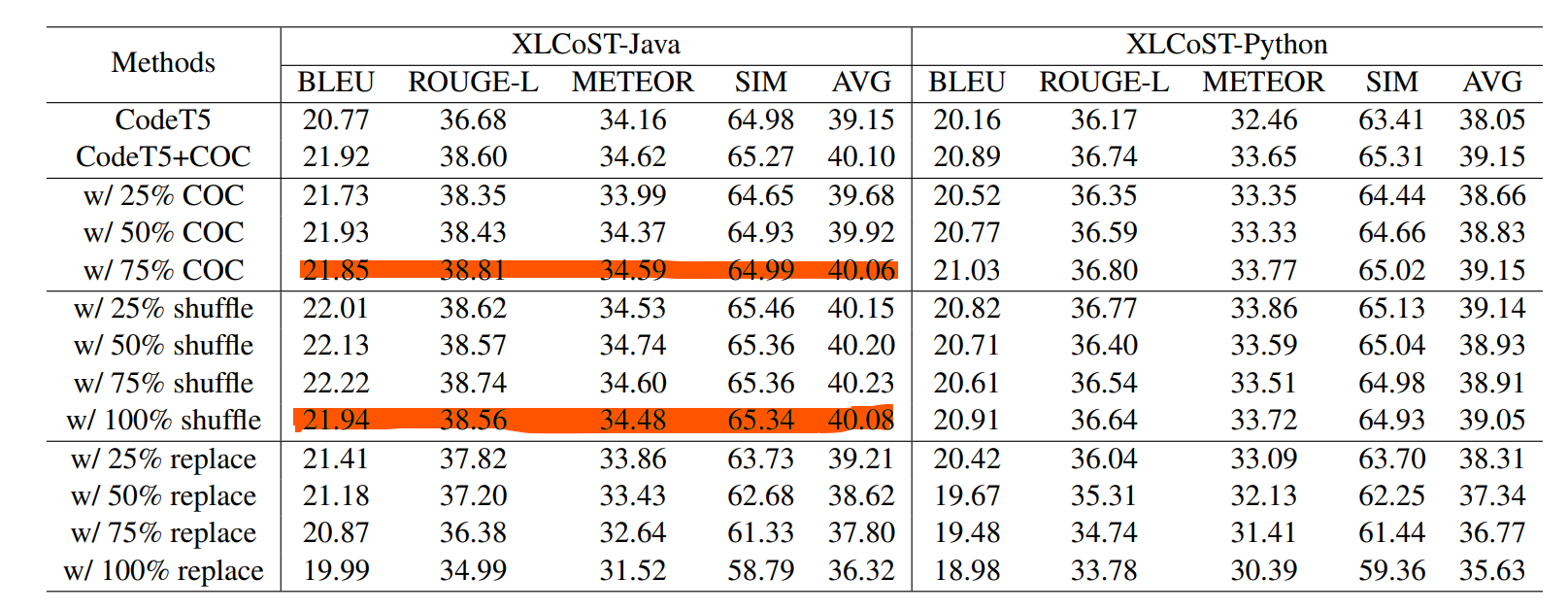
- 引入的注释链的数量越多(越多表明步骤越详细),代码摘要效果越好。(如右图:w/25%COC到w/75% COC,效果逐渐提升)
- 注释链的语义具有明显的影响。如右图:w/%replace替换了一定比例的注释步骤效果下降明显。
- 注释链中的步骤顺序几乎无影响,如右图w/ 100% shufe将步骤顺序完全打乱,效果几乎没有下降。说明模型并不关注顺序,只要语义正确以及详细就能从中学习好的摘要。
注释链对于代码摘要的提升:
注释链替换和打乱:
- 引入注释链和后验证模型能够提升代码预训练模型的代码总结性能
- 注释链的注释数量以及注释链的语义影响代码总结效果,但是注释链中的顺序几乎无影响
备注:
- Chain Of Comments (COC)
- BLEU(Bilingual Evaluation Understudy)
- 通过比较n-gram 精度(即生成文本中有多少 n-gram 出现在参考文本中)来评估质量。
- ROUGE-L(Recall-Oriented Understudy for Gisting Evaluation - Longest Common Subsequence)
- 基于最长公共子序列(LCS)计算召回率和 F1 值。
- METEOR(Metric for Evaluation of Translation with Explicit ORdering)
- 关注:精确率+召回+同义
- SIM(Code Semantic Similarity / Functional Equivalence)
- 关注:语义/功能/AST 相似性
注释链可以提升生成的摘要的信息量以及正确性,以及降低了模型的幻觉性
基于课程学习的自动代码摘要研究
代码语言模型(CLMS)在自动代码摘要领域已经取得了一定的效果。代码语言模型(CLMs)在生成摘要时,往往会严重依赖函数名。然而,现有的基于CLM的函数级摘要方法忽略了函数名对摘要的影响,导致CLM难以应对函数命名不清晰的情况。如果函数命名不当,CLM生成的摘要容易与原代码语义出现较大偏差。
微调后的CodeT5模型的表现如下:
def query_db(query,args=(),one=False): #命名良好
cur =g.db.execute(query, args)
rv = cur.fetchall()
return ((rv[0] if ry else None) if one else rv)
# 生成的摘要: query the database and return a list of dictionaries
def eqary_db(query,args=(),one=False): #命名不当
cur = g.db.execute(query, args)
rv= cur.fetchall()
return ((rv[0] if rv else None) if one else rv)
# 生成的摘要: execute a query in the euary database ,
以函数名为中心的数据增强
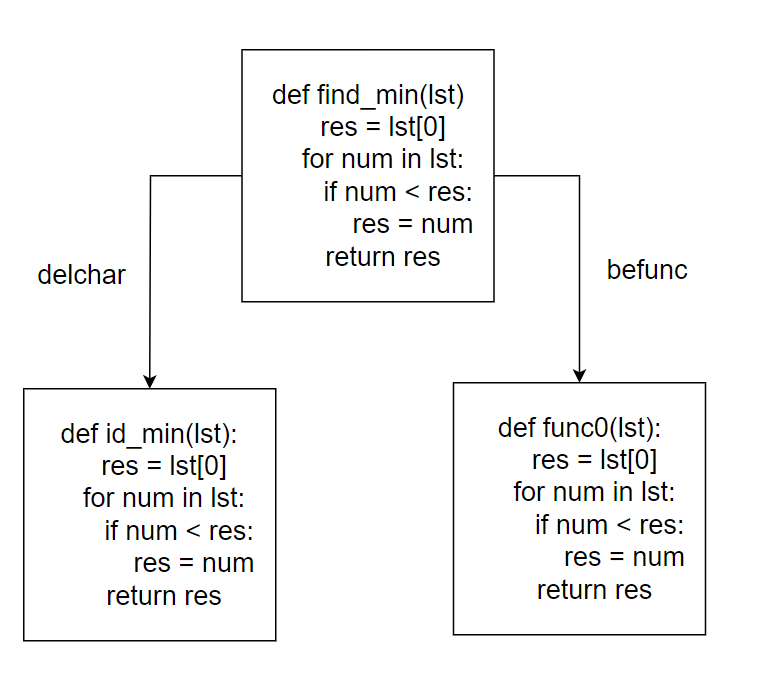
针对函数名设计不同的增强操作。如将函数名中的字符随机删除、把函数名整个替换
模拟现实中函数名命名不清晰的情况同时鼓励模型学习代码特征,而不是依赖不清晰的函数名
数据增强后的代码,与原代码是语义等价的,不改变其功能,以保证增强前后的代码能够与摘要正确匹配
课程学习就是让模型由易到难地训练,而不是像普通的训练那样让模型在所有数据上随机训练。
基于多专家高效微调的多语言代码摘要
多语言代码摘要: 让模型能够理解并概括来自不同编程语言的代码内容,生成对应自然语言格式的描述性文字。
其核心挑战在于: 模型既要捕捉多种语言之间公共特征,又要保留不同编程语言各自独有的语法与语义差异的特有特征。
扩展了多专家结构,引入一个捕获共性特征的通用专家以及多个专注于语言特定特征的专用专家。
- 单个通用专家永久激活,学习公共特征
- 多专用专家通过Global Top-K选择合适的专家,学习特有特征。
- 专家损失函数,保证专家的多样性同时促进训练平衡。
设计了一种新的专家损失函数,包括多样性损失和均衡损失,以确保专家能够针对不同语言进行专精,同时避免训练不均衡。
通过引入多语言LORA专家,分别捕捉不同编程语言的之间的公共特征和特有特征,再利用轻量级融合机制实现专家知识的高效整合,从而在实现高质量的多语言代码摘要生成,尤其提升在低资源语言上的效果。