
意图识别
定义
从用户输入的对话内容(如文本、语音等形式)中分析并判断出用户的目的或者意图,关联实际场景并输出结构化指令标签或关联参数。
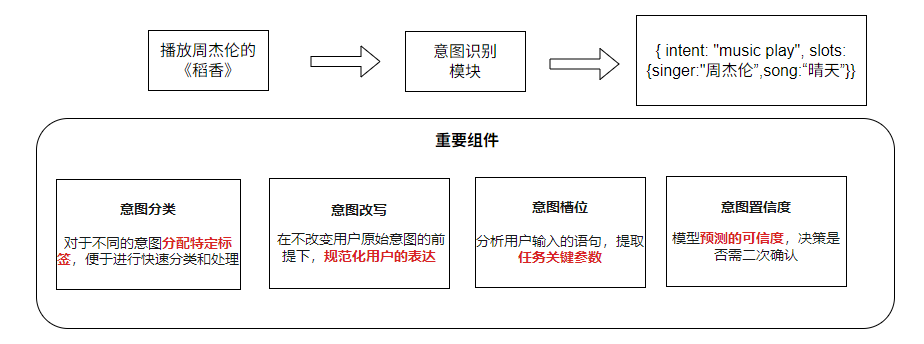
重要组件
- 意图分类
- 对于不同的意图分配特定标签,便于进行快速分类和处理
- 意图改写
- 在不改变用户原始意图的前提下,规范化用户的表达
- 意图槽位
- 分析用户输入的语句,提取任务关键参数
- 意图置信度
- 模型预测的可信度,决策是否需二次确认
与 LLM 结合的主流落地方案
| 方案 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 基础模型 + Prompt | 简单分类、低时延不敏感 | 开发成本低 | 垂直领域的准确性有限 |
| 基础模型 + RAG | 需要外部知识注入 | 支持新知识的理解 | 知识库的维护成本较大 |
| 小模型 + 微调 | 实时交互场景 | 低延迟、高准确性、低成本 | 依赖高质量的训练数据 |
预训练模型选择:
- BERT系列(适合短文本高精度场景,例如客服对话)
- GPT(适合长文本生成式意图识别,例如邮件自动分类)
LLM 意图识别的核心应用
语义理解的桥梁
- 任务精准触发: 基于模糊语言实现精确的下游任务路由
- 应用场景:任务模块路由 —— 长程任务将用户请求分配给相应任务模块
保障任务准确性与鲁棒性
- 领域知识注入: 通过RAG等手段保证垂域场景下的意图识别精度
- 冲突消解: 低置信度请求 + 重述机制保证意图识别鲁棒性
- 应用场景:动态上下文管理 —— 保证意图的连贯性,避免多轮交互导致目标偏离
支持复杂系统集成
- 多Agent协作枢纽: 拆解复杂指令意图,指派特定Agent
- 标准化接口: 统一意图标签对接下游API,降低系统改造成本
- 应用场景:资源分在均衡 —— 根据意图复杂度和调用频率分配计算资源
提升交互效率与体验
- 个性化适配: 结合用户画像等辅助手段动态调整潜在意图权重
- 低延迟响应: 小参数模型可以缩短响应时间,降低token消耗
- 应用场景:安全与合规过滤 ——拦截高风险意图,或对敏感操作添加二次确认环境
意图识别开发经验
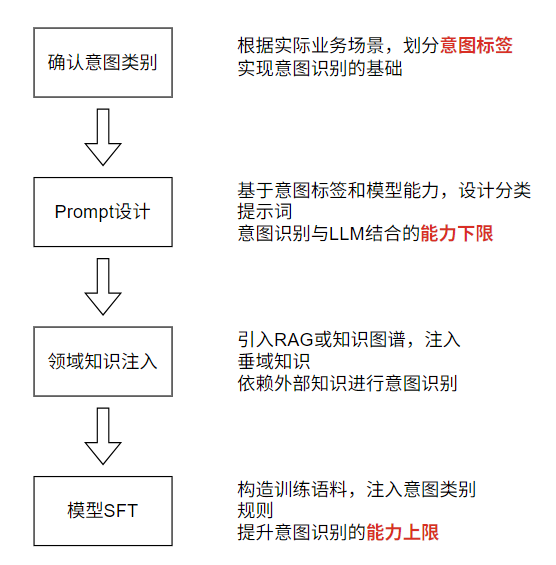
意图识别流程细节
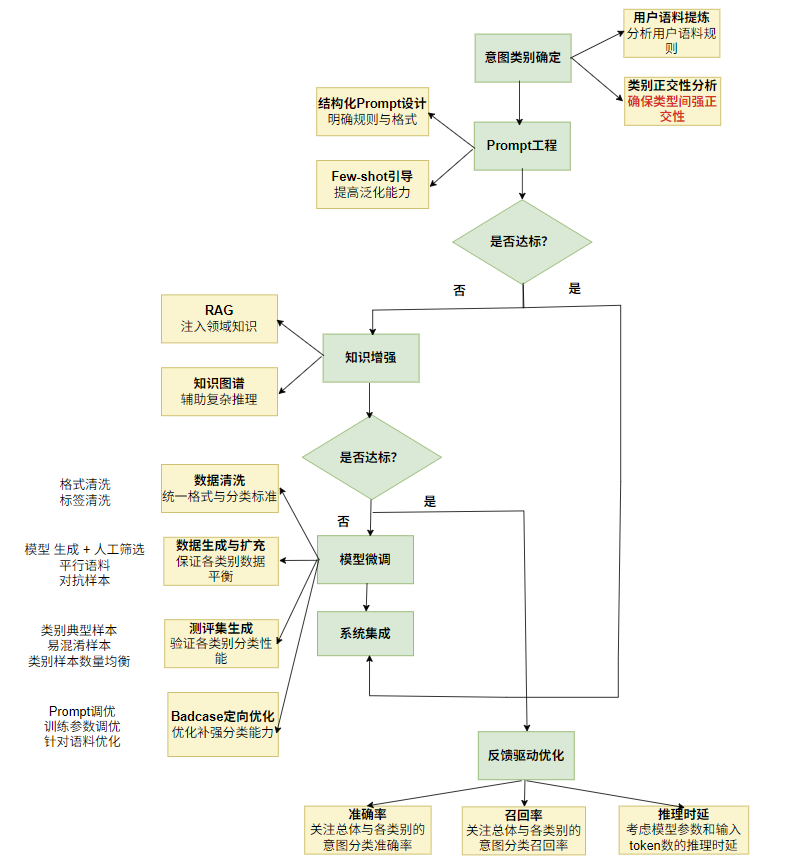
- 意图类别的确定
- 分析用户场景或者采集数据
- 明确场景规则,保证场景的正交性
- 设计意图类别标签
- 规则与标签的迭代优化
- Prompt设计
- 使用提示词强化类型名称 + 分类规则
- 意图识别提示词四段式定义
- 角色定义: 1. 你是一个善于分析用户问题并识别其意图的对话机器人
- 类别描述: 2. 你只能从以下意图中选择一项进行结果输出: 1. intent_1: description
- 分类规则: 3. 你可以借助以下规则来帮助进行意图判断:规则1:... ,规则2:...
- 输出规范: 4. 遵循上述规则,并严格按照以下格式进行输出: format
- 领域知识注入
- 构造知识库或者知识图谱,实现外部知识检索
- 引入意图改写和意图槽位,提升检索精度
- 考虑库维护成本,仅在高度依赖垂域知识Prompt精度不达标时使用此组件
- 模型SFT
- 构造训练数据(类别标签 + 训练格式)
- 利用 LLM 能力或人工扩充数据,保证类别均衡
- 人工生成各类别测评集
- 模型训练的测试结果进行针对性迭代优化
重要结论
参数规模与识别精度间的边际效应关系
- 模型参数量在意图路由上的性能存在边际效应
| LLM | Prompt | 全量SFT |
|---|---|---|
| Qwen3-0.6B(Baseline) | 8.87% | 98.56% |
| Qwen3-4B | 50.93% | 97.73% |
| Qwen3-8B | 40% | 97.73% |
| Qwen3-14B | 53.40% | 97.53% |
| Qwen3-32B | 73% | 97.53% |
具身智能意图识别: 不同参数量模型使用相同训练配置在上限(全量SFT数据)与下限(Prompt)方面的精度表现
- 模型的精度收益随着数据规模的增大而逐步递减,参数量越大的模型收到边际效应的影响越大
| LLM | 100% | 80% | 60% | 40% |
|---|---|---|---|---|
| Qwen3-4B | 97.73% | 96.91% | 96.49% | 93.40% |
| Qwen3-8B | 97.73% | 97.11% | 96.29% | 94.00% |
| Qwen3-14B | 97.53% | 97.32% | 96.70% | 95.10% |
| Qwen3-32B | 97.53% | 97.40% | 97.00% | 95.88% |
具身智能意图识别: 不同比例训练集进行SFT的精度
类别数量、模型参数量的意图识别下限
- 上下限数据结合业务测试情况,并参考业界在开源数据集(如情感分类、语义理解)上的测试结果。
- 实际业务中需要考虑具体的场景设置、输出格式构造、Prompt设计与优化。
| 类别数量\参数量 | 0.5B | 7B | 32B以及以上 | GPT-4o |
|---|---|---|---|---|
| 2 | 70%-80% | 85%-92% | 90%-95% | 95以上 |
| 3-5 | 60%-75% | 70%-85% | 80%-90% | 90%-98% |
| 6-10 | 30%-50% | 60%-70% | 70%-80% | 85%-95% |
| 10以上 | 30%以下 | 40%-60% | 60%-75% | 75%-85% |
不同类别数量与参数量模型使用Prompt可达成的理论精度经验值
- 当涉及复杂垂域问题时,意图分类性能会受到严重影响,需要进一步采取外挂知识库或SFT等方式进行优化。
- 意图类别数量越多,模型的准确率一般会下降,但高端模型(如 GPT-4)的下降幅度相比本地部署模型而言会比较小。
- 对于高类别数量的复杂场景,需要构造更加复杂的prompt(如思维链、特定准则)。
不同参数量的模型达成给定交付精度标准所需的SFT数据规模
若已实行Prompt工程,在不考虑垂域知识的前提下,以98%准确率作为交付标准,不同规模的分类模型所需数据量(包括对抗样本/平行样本)估算:
| 类别数量\参数量 | 0.5B | 7B | 32B以及以上 |
|---|---|---|---|
| 2 | 800-1000 | 100-300 | 100以内 |
| 3-5 | 1000-1500 | 300-500 | 100-300 |
| 6-10 | 1500-2500 | 500-1000 | 300-800 |
| 10以上 | 2500+ | 1000+ | 800+ |
训练方案决策的考量方面 —— 人力成本与交付效果的综合考量
- 模型规模与资源效率的权衡
- 意图类别数量与高识别精度的边际成本
- 推理时延与识别精度的平衡
工业应用中的意图识别开发 ———— 通用性延展
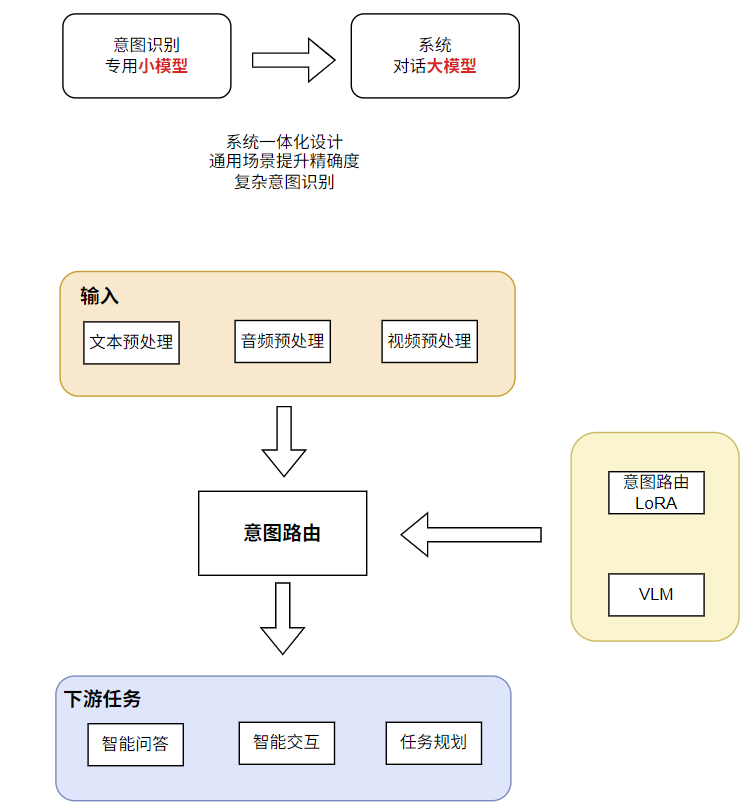
Multi-LoRA(多重低秩适应)是一种在单个基础大语言模型(LLM)上应用多个低秩适配模块的技术,可以在不修改核心模型权重的情况下,为模型赋予不同的专业化能力。